SAP HANA Certificado para Producción on Hyperconverged Infrastructure (HCI): Otro “Primero” para Nutanix AHV
La solución de SAP HANA nos propone el uso de servidores con capacidades de memoria tales que puedan albergar todos sus datos en Memoria. Esto es porque SAP HANA DB es una base diseñada para trabajar en memoria y gracias a esto poder responder en tiempos inigualables e incluir el uso concurrente de OLAP y OLTP. Es un salto enorme en el tipo de solución que puede ofrecer, sabiendo que la memoria puede ser accedida en tiempos del orden de los 100ns, y aún la más desafiante solución de almacenamiento puede responder en 100.000ns.

Las primeras implementaciones se realizaban en servidores físicos con sus discos internos en un ambiente denominado Appliance. Al tiempo apareció la opción de algo que SAP denominó TDI. El Appliance es una caja que ofrecer el fabricante con el soft precargado y que fue validado con SAP para cumplir cierta capacidad. Es la marca (Lenovo, Dell EMC, HPE, etc) quien configura y trabaja en conjunto con SAP y se conforma como una “caja” cerrada.
El ambiente TDI es aquel que se conforma con piezas soportadas, pero ahora no cerradas como el Appliance.
En la vida práctica, el Appliance resultaba técnicamente una forma simple y segura de iniciar un proyecto de SAP HANA, sin embargo, muchas veces inviable en costo.
Esto era porque los Appliance se armaban de Servidores High end, para poder cumplir con los requerimientos de memoria, y dado que la memoria acompaña al procesador (se requiere socket para poner Dimms de memoria) y en general en los SAPS resultantes eran varias veces mayor que el requerimiento.
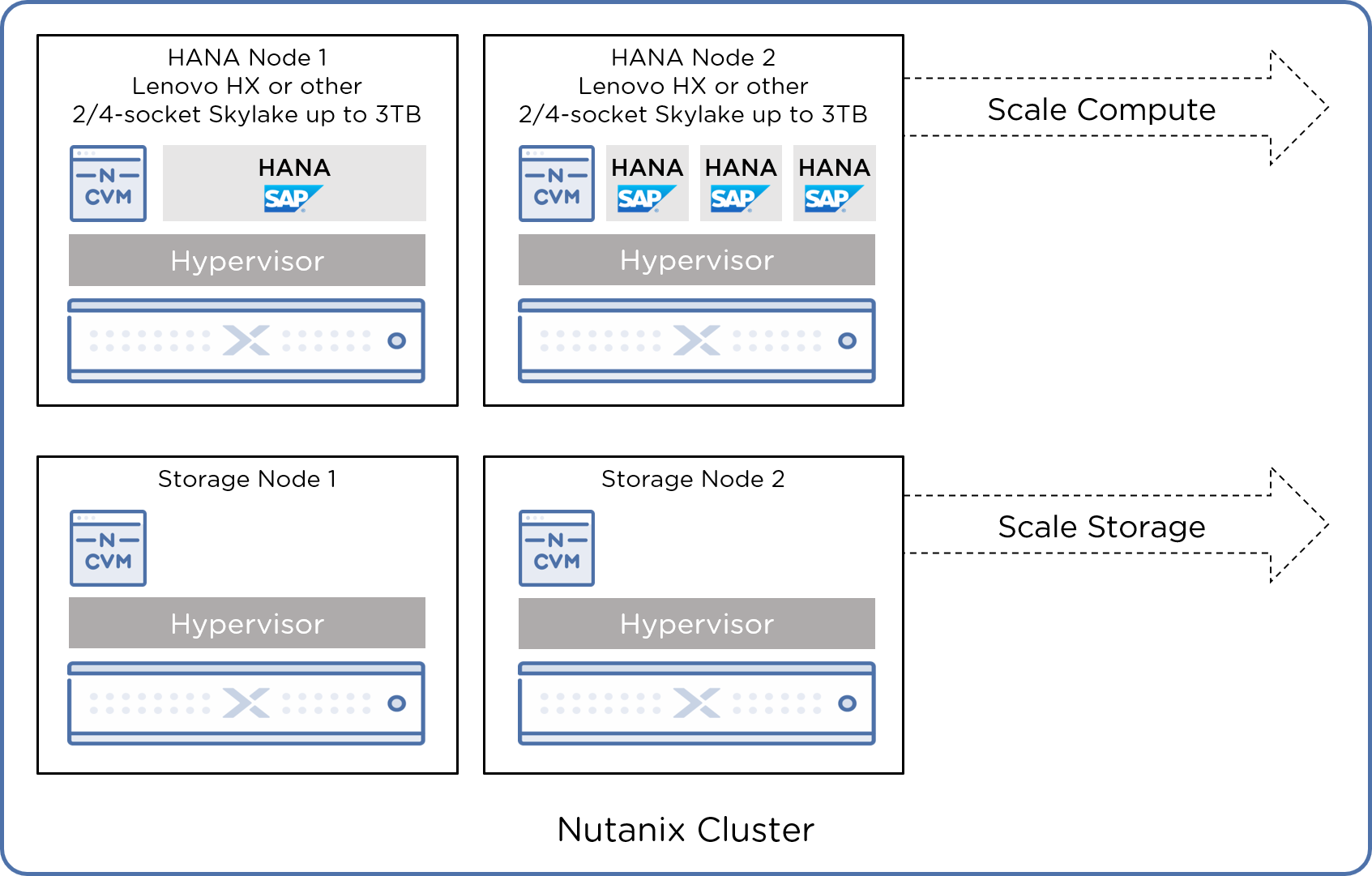
La Arquitectura TDI nos da la posibilidad de modificar los procesadores, y diseñar la solución más acorde al requerimiento, y de ahí hacer viable un proyecto de SAP HANA.
Adicionalmente, todo cliente SAP requiere la existencia de un ambiente productivo, y al menos un ambiente de Desarrollo, de QA y de Test.
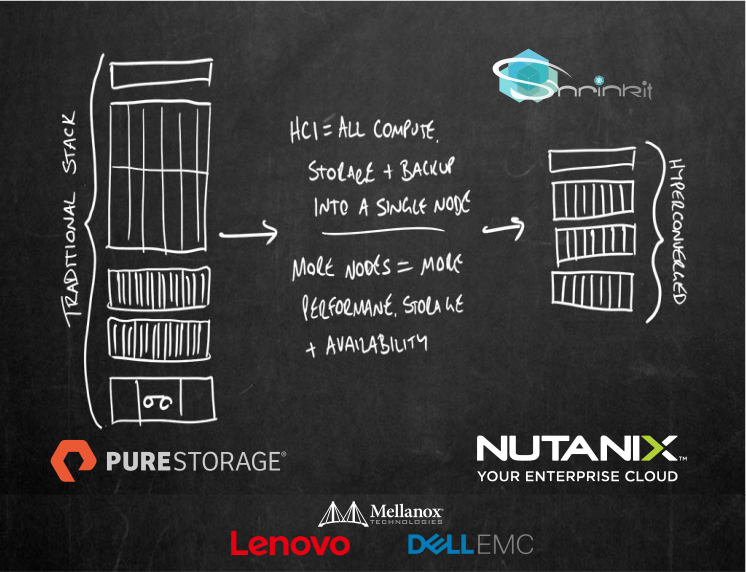
Ahí donde entra el beneficio de contar con la virtualización, y en especial la Hiperconvergencia.
A medida que necesitamos generar más ambientes, más beneficio de contar con el acceso del dato productivo para producir copias instantáneas.
Nosotros además vemos la oportunidad de hacer uso de Docker. De esta manera poder separar la instalación del dato e incluso integrarse en metodologías de DevOps en sintonía con otra aplicaciones de la empresa.
(ver: https://hub.docker.com/_/sap-hana-express-edition-incl-application-services )
En estos días estaremos dando una charla de SAP HANA sobre Nutanix.
De ser de interés puede ir a este link: https://shrinkit-it.com/eventos/